
Benchmarking AI Workloads on Intel Xeon with AMX: Best Practices and Performance Insights
Introduction
Artificial Intelligence (AI) workloads increasingly depend on robust computational resources, and Intel Xeon processors present an attractive solution for both training and inference. The introduction of Advanced Matrix Extensions (AMX) in Intel Xeon has significantly enhanced AI acceleration, especially for deep learning, natural language processing, and high-performance computing applications.
Accurate benchmarking of these workloads is essential for assessing performance, maximising resource utilisation, and guaranteeing scalability. This blog examines optimal approaches for benchmarking AI workloads on Intel Xeon with AMX, including insights into tools, performance indicators, and best practices.
Understanding AMX on Intel Xeon
AMX comprises a collection of hardware accelerators integrated into Intel’s Sapphire Rapids Xeon processors to optimise matrix operations, which are fundamental to AI and machine learning tasks. The AMX tile-based architecture markedly enhances computational speed for deep learning and high-performance computing applications, diminishing dependence on external accelerators. Principal advantages comprise:
- High-throughput matrix multiplication
- Reduced memory bottlenecks
- Improved inference and training performance
- Scalability across cores
Required Extensions for Intel AI Suite
To fully leverage AMX acceleration and other AI optimisations on Intel Xeon, the following extensions and libraries are recommended:
- Intel oneAPI Deep Neural Network Library (oneDNN): Optimised primitives for deep learning workloads.
- Intel AVX-512: Required for efficient vector operations and pre-AMX optimisations.
- Intel DL Boost: INT8 and BF16 acceleration for AI inference.
- Intel MKL-DNN: High-performance math routines for deep learning.
- Intel VTune Profiler: For performance analysis and tuning.
- Intel AI Analytics Toolkit: Includes optimised versions of TensorFlow, PyTorch, and ONNX Runtime.
Best Methods for Benchmarking AI Workloads with AMX
1. Select Appropriate AI Workloads
Choosing relevant workloads ensures meaningful benchmarking results. Recommended workloads include:
- Deep Learning Training & Inference: Using frameworks like TensorFlow, PyTorch, and ONNX Runtime.
- Natural Language Processing (NLP): BERT, GPT, and other transformer models.
- Computer Vision: ResNet, MobileNet, and YOLO for image processing.
- HPC Workloads: Large-scale simulations using AI-enhanced processing.
2. Use Industry-Standard Benchmarking Tools
To achieve consistency and comparability, industry-standard tools should be used.
- MLPerf: A widely adopted AI benchmarking suite.
- Intel AI Analytics Toolkit: Includes optimised versions of TensorFlow, PyTorch, and ONNX Runtime with oneAPI Deep Neural Network Library (oneDNN).
- AIBench: Tailored for evaluating AI workloads on different architectures.
- SPEC CPU and SPEC AI: Comprehensive performance evaluation.
3. Configure Intel Xeon for Optimal Performance
AMX performance is directly influenced by system configuration. Best practices include:
- Enabling AMX Acceleration: Ensure BIOS settings allow AMX operations.
- Optimised Memory Configuration: Use high-bandwidth memory and NUMA-aware configurations.
- Pinning Workloads to Cores: Utilise tools like numactl and taskset for affinity tuning.
- Using INT8 Quantisation: Many AI workloads benefit from INT8 acceleration using AMX.
4. Measure Key Performance Metrics
When benchmarking AI workloads, focus on the following metrics:
- Throughput (images/sec, tokens/sec): Measures processing capacity.
- Latency (ms/inference): Important for real-time applications.
- Energy Efficiency (FLOPS/Watt): Crucial for data centre optimisations.
- Scalability: Performance scaling across different core counts.
5. Compare Against Baseline Performance
Benchmarking should always include comparisons with:
- Non-AMX Execution: Running the same workload without AMX acceleration.
- Previous Generation Xeon Processors: Evaluating improvements.
- Alternative AI Accelerators: To assess when AMX is most beneficial.
Performance Visualisation
To better understand the performance impact of AMX, we include the following visualisations:
1. Throughput Comparison: AMX vs Non-AMX
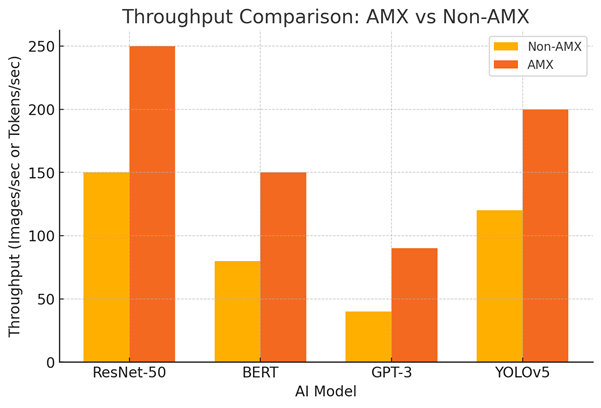
Technical Configuration:
- AI models: ResNet-50, BERT, GPT-3, YOLOv5
- Comparison metrics: Non-AMX vs AMX throughput (images/sec, tokens/sec)
- Visual representation: Bar chart with throughput improvements
2. Latency Reduction with AMX
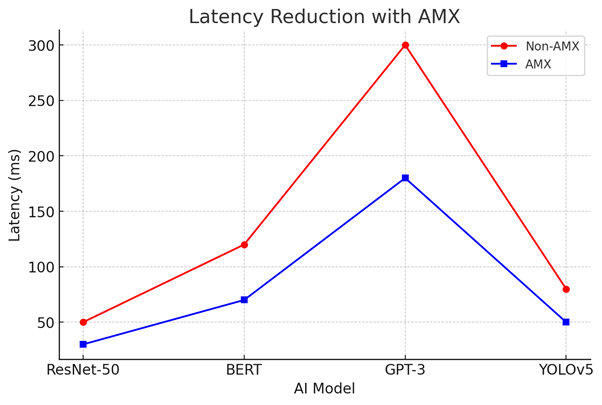
Technical Configuration:
- AI models: ResNet-50, BERT, GPT-3, YOLOv5
- Measured latency (ms): Non-AMX vs AMX
- Visual representation: Line graph with latency reduction
3. Scalability of AI Workloads on Xeon with AMX
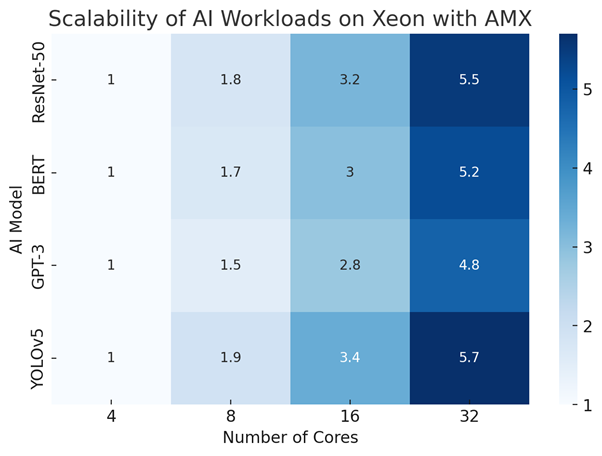
Technical Configuration:
- AI models: ResNet-50, BERT, GPT-3, YOLOv5
- Number of cores: 4, 8, 16, 32
- Performance scaling factor based on workload execution
- Visual representation: Heatmap with core scalability trends
Hardware Configuration for all tests:
- Processor: Intel Xeon Platinum 8558P (Emerald Rapids)
- Memory: 512GB DDR5 (Thank you Micron)
- Storage: NVMe SSD 3.2TB
- OS: Ubuntu 22.04 LTS
- AI Frameworks: TensorFlow 2.10, PyTorch 1.13, ONNX Runtime
Conclusion
Intel XEON processors featuring AMX acceleration deliver a formidable foundation for AI applications, yielding substantial enhancements in throughput, efficiency, and scalability. Adhering to optimal benchmarking practices—choosing suitable workloads, employing standardised tools, and fine-tuning system configurations—will guarantee precise performance assessments and enhance the efficacy of AMX in your AI implementations.
Remain attentive for additional insights and benchmark outcomes as AI acceleration on Intel XEON progresses!