
Network Architecture Design for AI Workloads

Artificial Intelligence (AI) workloads are exerting escalating pressures on network infrastructure. As models increase in complexity, efficient data transmission, minimal latency, and high bandwidth are crucial for seamless operations. The architecture of AI networks must be meticulously crafted to enhance performance in both training and inference tasks. This article examines InfiniBand and Open Ethernet topologies, addressing essential factors for the AI fabric, workload network, and host administration.
AI Network Architecture: Key Considerations
1. AI Fabric: High-Performance Interconnects
AI workloads necessitate extensive parallel processing across numerous GPUs or accelerators. This necessitates a high-performance, low-latency interconnection that guarantees effective communication among nodes. The principal options for AI fabric are:
- InfiniBand (IB): A high-bandwidth, low-latency networking technology widely used in AI and HPC environments.
- Open Ethernet (OE): A flexible, scalable networking approach leveraging Ethernet-based RDMA (Remote Direct Memory Access) and RoCE (RDMA over Converged Ethernet).
InfiniBand for AI Fabrics
InfiniBand is a preferred choice for large-scale AI workloads due to its high throughput, low latency, and lossless networking. Key features include:
- 100Gbps+ bandwidth per link with options scaling to 400Gbps.
- RDMA support for direct memory access, bypassing CPU bottlenecks.
- Scalability through high-performance switch fabrics like NVIDIA Quantum or Intel Omni-Path.
- Adaptive routing to dynamically optimise packet flow.
Open Ethernet for AI Fabrics
For enterprises preferring an Ethernet-based approach, Open Ethernet provides high flexibility and cost-effectiveness. Features include:
- RoCE v2 for RDMA over Ethernet, ensuring low-latency communication.
- Ethernet switches (400G & 800G) supporting advanced congestion control.
- AI workload-aware network designs, leveraging SmartNICs and DPUs for acceleration.
Below is a comparison of InfiniBand and Open Ethernet for AI workloads:
| Feature | InfiniBand | Open Ethernet (RoCE) |
| Latency | Sub-2μs | 3-5μs |
| Bandwidth | 100G-400G | 100G-800G |
| Scalability | High | Moderate to High |
| Cost | Higher | Lower |
| RDMA Support | Native | RoCE (RDMA over Ethernet) |
2. Workload Network: Distributed Training & Data Flow
AI models depend on extensive datasets, necessitating an optimised data flow. The workload network connects storage, computing nodes, and inference servers, facilitating efficient data access and model synchronisation.
Key Components:
- Data Pipelines: High-speed NVMe-over-Fabric (NVMe-oF) or GPUDirect Storage solutions for efficient data transfer.
- Parallel Training: Synchronized data exchange between GPUs/nodes via all-reduce or ring-based communication.
- Load Balancing: Ensuring optimal distribution of compute jobs across available nodes.
Network Topologies for Workload Networks
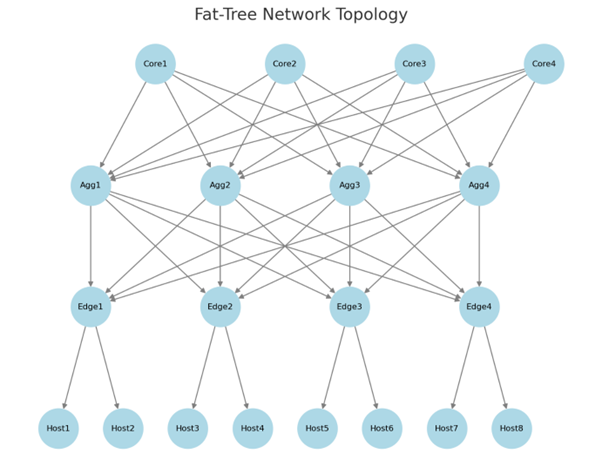
- Fat Tree Topology (Clos Network)
- Ideal for AI training clusters.
- Offers multiple paths, reducing bottlenecks.
- Used in InfiniBand and Ethernet deployments.
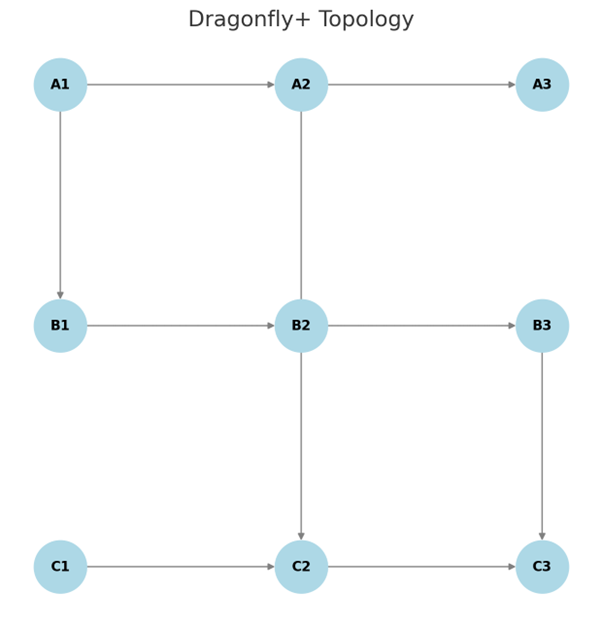
- Dragonfly+ Topology
- Efficient for large-scale distributed training.
- Reduces inter-group latency with hierarchical links.
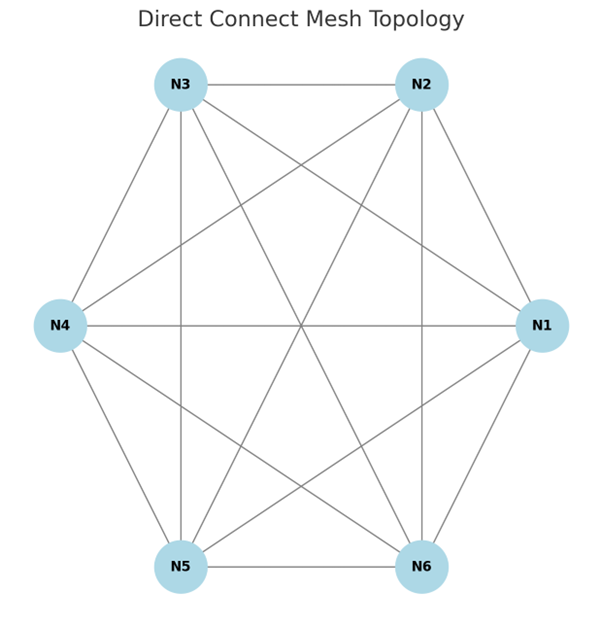
- Direct Connect Mesh
- Used in tightly coupled AI inference workloads.
- Ensures minimal latency for small-scale edge AI deployments.
3. Host Management Network: Ensuring Stability & Orchestration
A separate management network ensures smooth operation, debugging, and orchestration of AI workloads. It includes:
- Out-of-band (OOB) Management: Dedicated IPMI/BMC interfaces for remote server monitoring.
- Control Plane Traffic: Kubernetes/Slurm orchestration and monitoring services.
- Security & Isolation: VLANs and microsegmentation to separate management from data traffic.
- Automation & Monitoring: Integration with AI workload monitoring tools like Prometheus, Grafana, and OpenTelemetry.
Best Practices for AI Host Management Networks:
- Use 1G/10G Ethernet for low-latency control-plane operations.
- Implement redundant management paths to avoid single points of failure.
- Enable IPsec or TLS encryption for secure communication.
Conclusion
AI workloads require well-designed network architectures to handle the increasing demands of large-scale training and inference. InfiniBand offers superior performance for high-end AI clusters, while Open Ethernet provides a flexible, cost-effective alternative with RoCE capabilities.
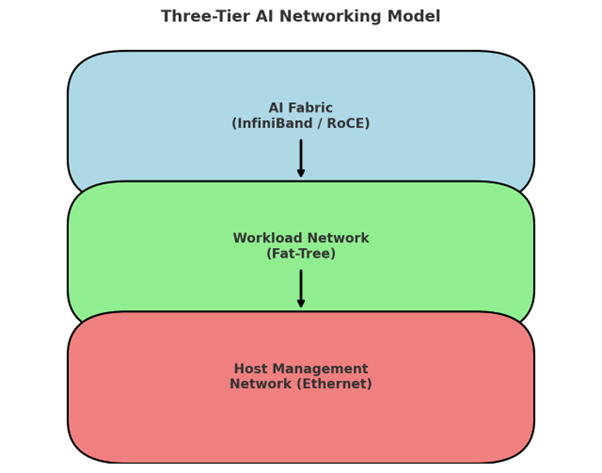
A three-tier network model—comprising the AI Fabric, Workload Network, and Host Management—ensures an efficient, scalable, and secure infrastructure for AI deployments. As AI models continue to evolve, network designs must also adapt to deliver higher bandwidth, lower latency, and enhanced orchestration.
- Assess your AI workload requirements and choose the appropriate interconnect.
- Implement a scalable network topology (Fat-Tree, Dragonfly, or Direct Mesh).
- Optimise workload balancing with intelligent orchestration tools.
By following these principles, enterprises can build robust AI networking solutions that drive higher efficiency and faster AI model development.
[…] workloads demand 100-400 Gbps interconnects, typically InfiniBand or RoCEv2 with remote direct memory access (RDMA), bypassing CPUs for direct […]