
How Easy Is It to Deploy AI Tools? NVIDIA vs Intel Compared

One of the most frequent questions I’m asked by customers embarking on AI projects—whether it’s training deep learning models, running inference workloads at the edge, or scaling machine learning in a hybrid environment—is:
“How easy is it to deploy the tools?”
The answer often surprises them. While NVIDIA has been the dominant player in AI hardware, Intel has rapidly caught up—especially when it comes to software simplicity, ecosystem integration, and deployment flexibility.
In this post, I’ll break down the real-world experience of deploying AI tools from both NVIDIA and Intel, across bare metal, VMs, and containerized environments. We’ll look at the common pitfalls, show you what installations look like, and compare each ecosystem’s pros and cons.
1. Why Deployment Matters—and Where Customers Struggle
For many teams, AI success is hindered not by model accuracy or data pipelines—but by toolchain friction. Typical customer issues include:
- Mismatch of driver/tool versions (especially with CUDA/cuDNN)
- Lack of clarity around ecosystem tools (e.g., which SDKs are required)
- Difficulty integrating into VM/container environments
- Long setup times and cryptic errors, particularly for first-time setups
These pain points often lead to delayed projects, inconsistent environments across teams, and underutilized hardware.
2. Ease of Deployment: Bare Metal, VMs, and Containers
| Deployment Mode | NVIDIA | Intel |
| Bare Metal | CUDA toolkit must match driver/kernel versions; more manual setup | Intel® AI Tools install in one-line scripts; fewer dependency conflicts |
| VMs | Requires GPU passthrough or vGPU setup (complex) | CPU-optimized out of the box; no passthrough needed |
| Containers | NVIDIA NGC containers are well-maintained but often large and proprietary | Intel OpenVINO and AI Toolkit containers are lean and integrate easily with Kubernetes and OpenShift |
Training vs ML vs Inference:
- Training: NVIDIA dominates with CUDA-accelerated libraries (but setup is sensitive). Intel’s oneAPI toolkit supports training with PyTorch and TensorFlow using CPU or Habana Gaudi accelerators.
- Machine Learning: Intel’s scikit-learn and XGBoost optimizations often outperform NVIDIA for CPU workloads.
- Inference: Intel OpenVINO can deploy to CPU, GPU, and VPU with one API—while NVIDIA TensorRT requires GPU and tightly coupled CUDA libraries.
3. Download & Install Examples

✅ Intel AI Toolkit (Bare Metal Install)
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/19261/l_AIKit_p_2024.1.0.620.sh
chmod +x l_AIKit_p_2024.1.0.620.sh
sudo ./l_AIKit_p_2024.1.0.620.sh
Or install via oneAPI APT/YUM repo:
sudo apt install intel-basekit intel-aikit
- OpenVINO Toolkit: https://www.intel.com/openvino
- Intel AI Tools: https://www.intel.com/oneapi
Or if you prefer a GUI experience, you can use the AI Tools website where you can specify the type or workload and the intended architecture (CPU or GPU) which will generate a script for you to copy/paste into your Bare Metal, VM or Container instance: https://www.intel.com/content/www/us/en/developer/topic-technology/artificial-intelligence/frameworks-tools-selector.html
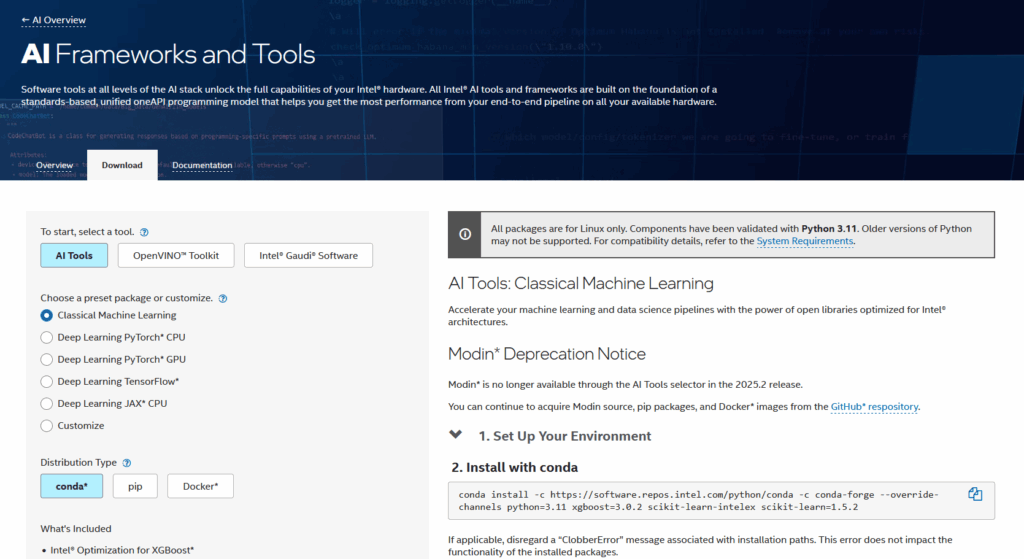
✅ NVIDIA CUDA Toolkit (Bare Metal Install)
wget https://developer.download.nvidia.com/compute/cuda/12.3.1/local_installers/cuda_12.3.1_545.23.08_linux.run
sudo sh cuda_12.3.1_545.23.08_linux.run
Please note: Driver/toolkit version must match.
Then install cuDNN separately.
- NVIDIA CUDA: https://developer.nvidia.com/cuda-toolkit
- NVIDIA NGC Containers: https://ngc.nvidia.com/catalog/containers
4. Pros and Cons
| Feature | NVIDIA | Intel |
| Installation Simplicity | ❌ Driver/toolkit mismatch common | ✅ One-click or APT/YUM |
| Training Performance (GPU) | ✅ Industry leading | 🚧 Only Gaudi 2/3 accelerators |
| Inference Flexibility | ❌ GPU only | ✅ CPU, GPU, VPU |
| Container Support | ✅ Mature NGC ecosystem | ✅ Open-source, lightweight containers |
| Compatibility with Open Source | ⚠️ Often proprietary stack (TensorRT, cuDNN) | ✅ Broad framework compatibility |
| Virtualization Support | ❌ GPU passthrough required | ✅ Works natively with vCPUs |
| Ease of Debugging | ⚠️ CUDA errors can be obscure | ✅ Easier stack tracing with standard Python/LLVM tools |
5. Summary Comparison Table
| Category | Winner |
| Installation Speed | Intel |
| Out-of-the-box VM Support | Intel |
| Training on GPUs | NVIDIA |
| Inference on CPUs/VPUs | Intel |
| Container Ecosystem | Tie |
| Toolchain Complexity | Intel (simpler) |
6. Summary: Which Is Easier to Deploy?
If you’re looking for rapid time-to-value, especially for inference and hybrid CPU/GPU workflows, Intel’s AI toolchain is significantly easier to deploy—whether on bare metal, VMs, or containers.
NVIDIA excels when performance at scale is paramount for GPU training—but it comes with more ecosystem lock-in, version sensitivity, and setup overhead.
For most enterprise deployments, Intel’s simpler, open, and flexible toolset offers an edge in productivity.